Describe a three-step process for domain partitioning.
Three Steps to Domain Partitioning Process
Using the domain resources as your source, you can break down the process of domain partitioning into three steps.
Three-step Process
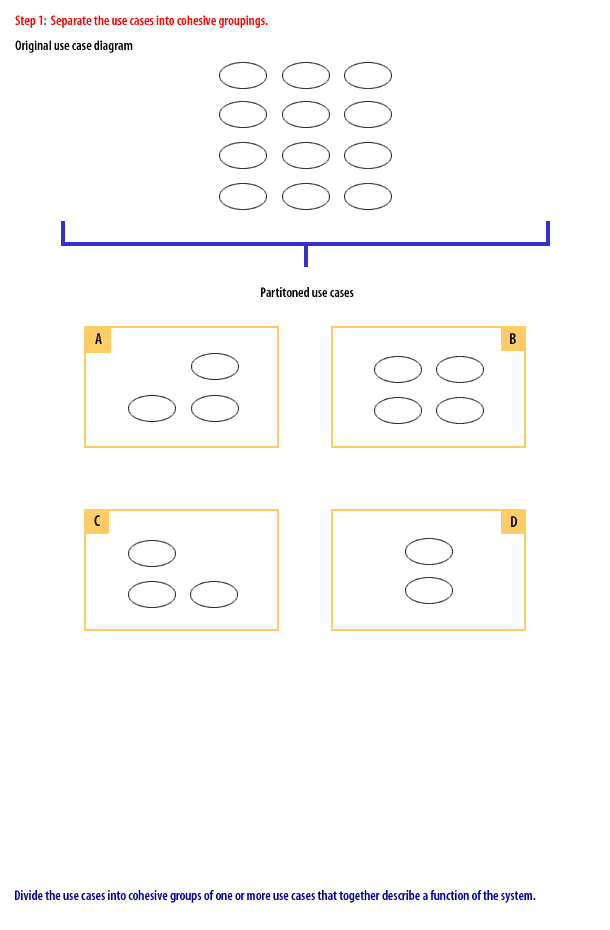
Step 1: Separate the use cases into cohesive groupings.
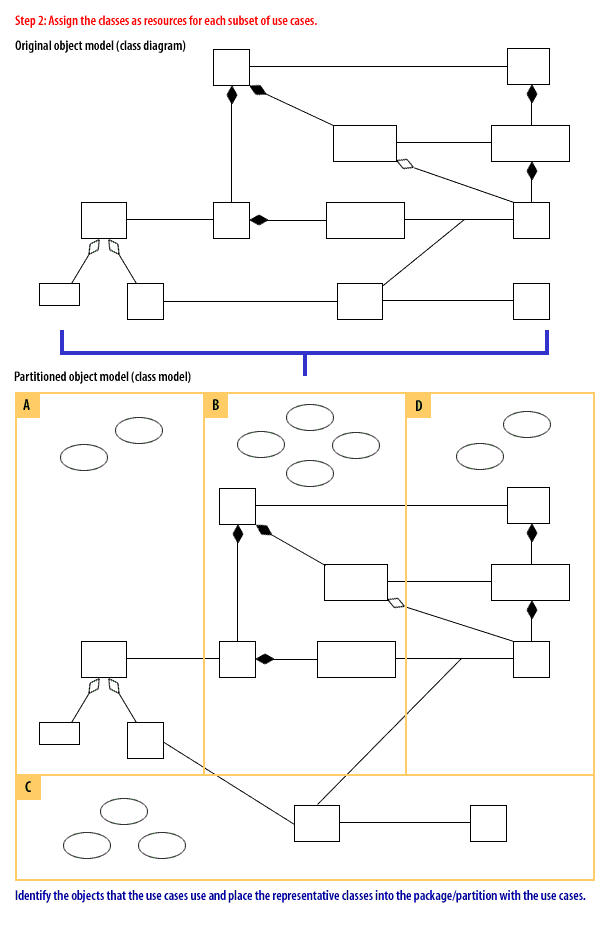
Step 2: Assign the classes as resources for each subset of use cases
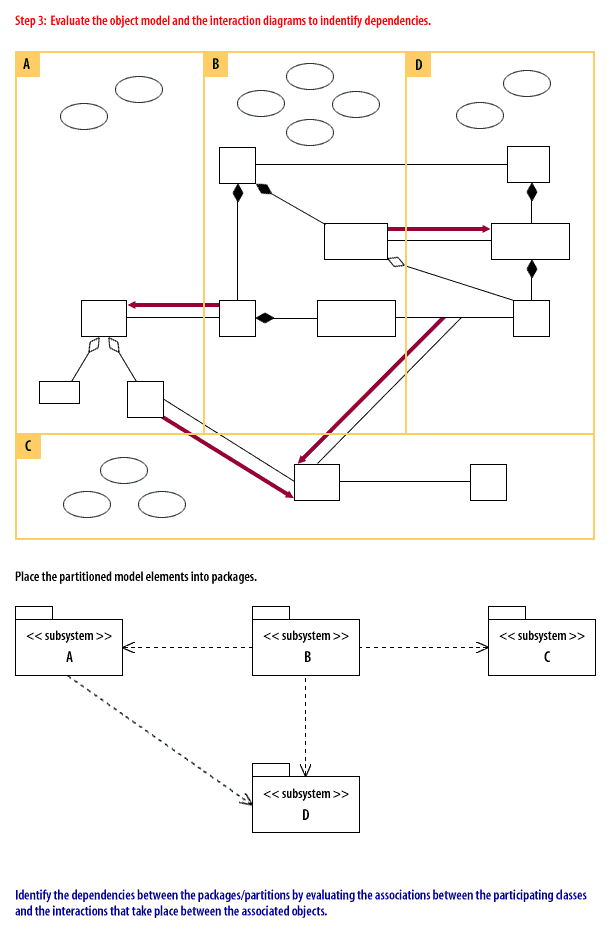
Step 3: Evaluate the ojbect model and the interaction diagrams to identify dependencies
The following three diagrams describe the 3 step process.
UML Domain Partitioning Process described in 3 Steps
Step 1: Separate the use cases into cohesive groupings. Divide the use cases into cohesive groups of one or more use cases that together describe a function of the system.
Step 2: Assign the classes as resources for each subset of use cases
Identify the objects that the use cases use and place the representative classes into the package/partition with the use cases.
Step 3: Evaluate the ojbect model and the interaction diagrams to identify dependencies
Identify the dependencies between the packages/partitions by evaluating the associations between the participating classes and the interactions that take place between the associated objects.
Remember that, as with every modeling process, the tasks are iterative. Take a stab at a use case partitioning which seems to make sense. Move to the next step and try to assign the classes. This attempt will very likely reveal some errors in your thinking or make you think about the partitioning differently. Continue to refine the partitions until you are satisfied that they adequately represent the desired solution. You can always continue the refinement process by soliciting input from others. Use the diagrams to communicate your ideas and to capture insights gained through reviews. This practice will keep the diagrams current with your understanding of the requirements.
Work Products versus Documentation
Try not to get in the habit of taking notes, and then trying to update diagrams later. The diagrams will become just another bothersome documentation task and lose their true value as tools to assist in the modeling process.
Use of Common Diagram Types
Despite the fact that UML is deliberately non-method-specific, it inevitably inherited a number of features that are consistent with the general approach used by the main contributing methods. One such feature is the use of common diagram types for both analysis and design. This favors the elaborative approach of adding detail to a modified analysis model in order to produce a design model. It reflects the principle that software objects are abstractions of concepts in the real world. It is also convenient for iterative development because it avoids the need for repeated transformations between diagram types for different phases. Earlier versions of UML allowed the modeler to use freeform textual descriptions to describe the intended behavior of some parts of the model, such as methods. UML treats these descriptions as uninterpreted strings. The blame is therefore on the modeler to ensure that the descriptions are consistent with the rest of the model, and that the behavior which is described actually takes place as specified when the system is implemented.
What Is Continuous Integration?
The process of integrating software is not a new problem. Software integration may not be as much of an issue on a one-person project with few external system dependencies, but as the complexity of a project increases (even just adding one more person), there is a greater need to integrate and ensure that software components work together early and often. Waiting until the end of a project to integrate leads to all sorts of software quality problems, which are costly and often lead to project delays. Continuous integration addresses these risks faster and in smaller increments. Martin Fowler describes CI as:
"A software development practice where members of a team integrate their work frequently, usually each person integrates at least daily, leading to multiple integrations per day. Each integration is verified by an automated build (including test) to detect integration errors as quickly as possible. Many teams find that this approach leads to significantly reduced integration problems and allows a team to develop cohesive software more rapidly.