Describe the Architectural Layering in a Three-Tier Approach.
Describe the Architectural Layering in a Three-Tier Approach
In a three-tier architecture, the system is divided into three distinct layers, each with specific roles:
Presentation Layer (Client): This is the user interface (UI) or front-end that interacts with the end user, usually a web or mobile app.
Application Layer (Business Logic): This middle layer handles the business logic and data processing, connecting the client to the database.
Data Layer (Database): The back-end where data is stored and retrieved, often a database server.
This model enhances scalability, maintainability, and separation of concerns.
The Move to Three Tier Architecture
In the lesson on two-tier architecture you learned how a system could be partitioned into two segments. The reasoning that guided the partitioning process followed the principles of high cohesion and loose coupling. This reasoning identified a problem with the two-tier approach. The problem is that the logic that controls the system was split between the client applicati0on and the central computer. This setup resulted in redundancy between the two tiers and between systems. Furthermore, a great deal of the logic in a system is very standard in the form of transactions; the same standard transactions may be used by many client applications. Following our simple pattern, why not split the system again and put all of this commonly used logic into its own partition?
Then you could provide an interface to it for all of the client applications.
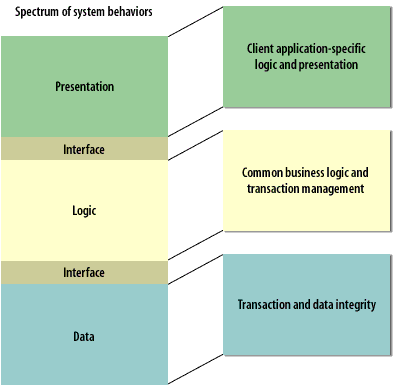
Spectrum of system behaviors: 1) Presentation, 2) Logic, 3) Data
The image illustrates a three-tier architecture with labels and color coding to represent different system behaviors and their interactions:
Presentation Tier (Green): Labeled as "Client application-specific logic and presentation," indicating it handles user interface and application-specific interactions.
Logic Tier (Yellow): Contains "Common business logic and transaction management," suggesting it manages the core functionality and business rules of the application.
Data Tier (Blue): Defined by "Transaction and data integrity," emphasizing its role in data storage, access, and ensuring data accuracy and security.
Each tier is separated by an "Interface" layer, signifying the defined communication protocols or APIs that allow each tier to interact securely and efficiently without direct coupling. This separation enhances scalability, security, and maintainability of the system.
The result is a high degree of reuse (of the business logic) and simpler, less intelligent client applications. The client application does not need to know very much business logic. They only need to know what transactions (or services) are available and valid for what they are helping the user accomplish.
Large or unknown number of users: The users may be unknown in advance or the number of users is very large. Either situation makes it difficult to anticipate the user interface design requirements.
Limited number of users: Few users will require access to the application. This might be because the application is very specialized or because there is a need for a higher degree of security.
Interfaces
Diverse users requiring alternative interfaces: The users are diverse and consensus would be difficult if not impossible. The interface needs to provide some degree of versioning or customization. The best way to provide this is to separate the interface from the application logic.
Standard interface: The user interface is well-defined and standardized. Changes are limited or easily controlled through access to the known group of users.
Implementation
Distributed implementation: The application needs to be installed in a number of locations. Likewise, the data might be separated by location. For example, regional sales may be stored in the regions rather than centralized.
Local implementation: The application will only be used in one, or a few, predetermined locations.
Workstation configurations
Unknown or uncontrollable user workstation configurations: You have no control over the type of workstation or the configuration of the workstations.
Control of the user workstation configurations: The client resources will be configured to handle most of the processing for the application. The resources can be controlled if the application requirements change.
Encapsulation:
Another benefit arises from this approach to system architecture. Each partition encapsulates a discrete set of functions. The internal workings of each partition are hidden from other parts of the system. Hiding the internal design allows developers to alter the internal design of one partition without interfering with other partitions. For example, the database could change or the business logic service could be rerouted to another server without the client application ever knowing or caring.